Data Modeler
Start at the beginning
Every divbloxPHP project starts with the data model. A well designed data model can be the difference between an app that works brilliantly and one that just doesn't cut it. The divbloxPHP data modeler allows you to create and manage your app's data model in a visual environment. Once a data model is defined, the Data Modeler ensures that the underlying databases are synchronized to its specification and then generates the object relational model classes. This makes communication with your databases seemless and easy to manage in an object oriented way.
Vocabulary
info
Entity: The definition of an object that will be presented by a class in code and by a table in the database
Basic Data Modeling Concepts
The data model allows you define the following:
- All of your entities, their attributes, attribute types and their relationships to other entities
- The user roles that your app will allow for
Below is the data model for a simple example we will use iin this section.
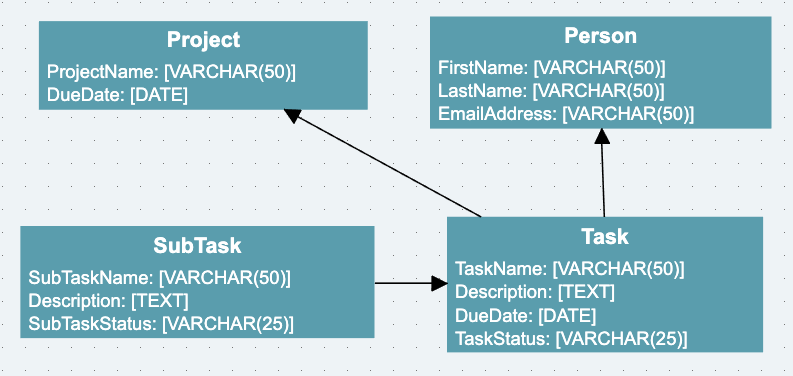
The data model in the above example describes the following:
- 4 Entities: "Person","Project","Task","SubTask"
- A Person is described by 3 attributes: "FirstName","LastName","EmailAddress" of type "VARCHAR(50)","VARCHAR(50)" and "VARCHAR(50)"
- A Project is described by 2 attributes: "ProjectName","DueDate" of type "VARCHAR(50)" and "DATE"
- A Task is described by 4 attributes: "TaskName","Description","DueDate","TaskStatus" of type "VARCHAR(50)","TEXT","DATE" and "VARCHAR(50)"
- A SubTask is described by 3 attributes: "SubTaskName","Description","SubTaskStatus" of type "VARCHAR(50)","TEXT" and "VARCHAR(50)"
- A Task has a single relationship to both Person and Project, meaning a person and/or project can have multiple tasks associated with it
- A SubTask has a single relationship to a Task, meaning a Task can have multiple SubTasks linked to it
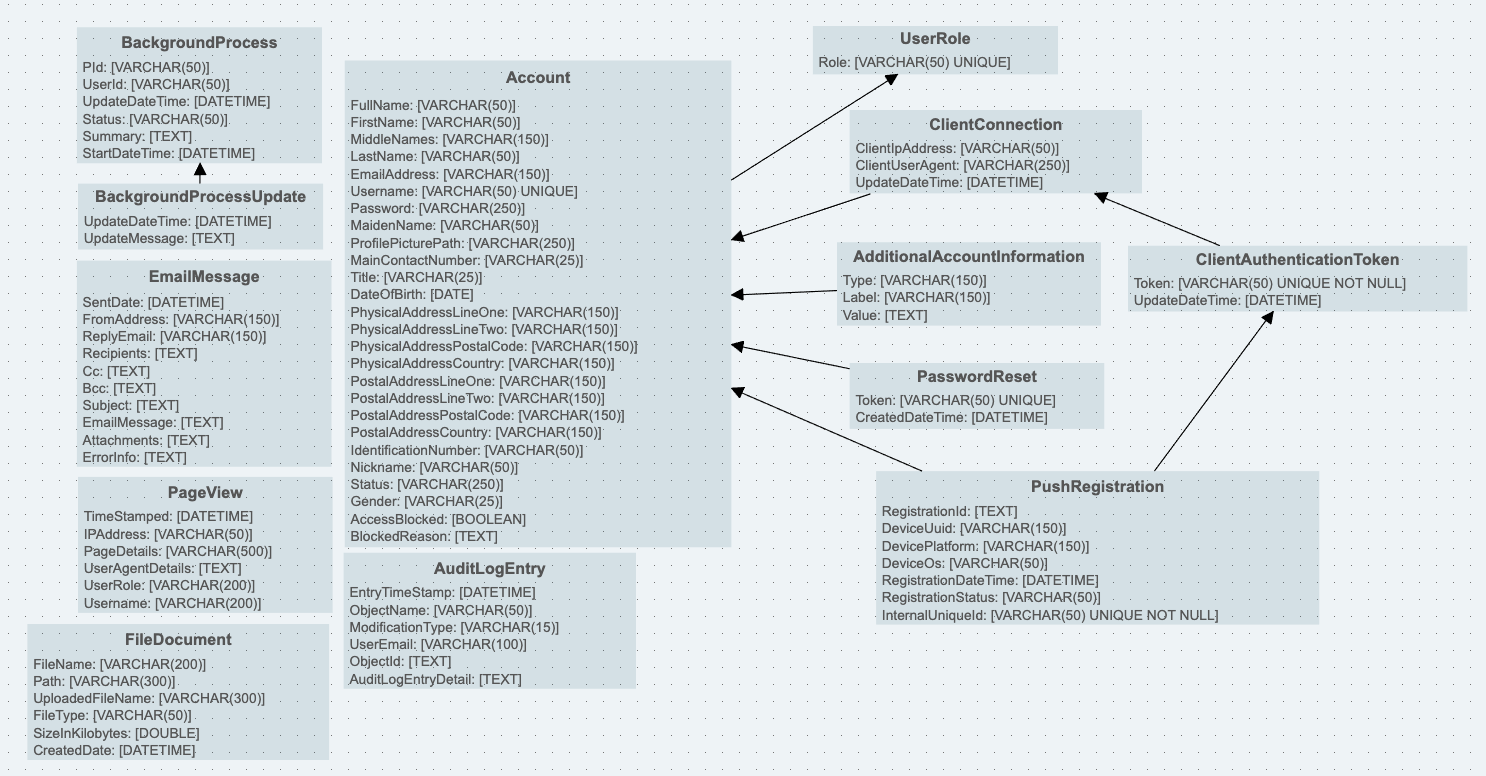
The Divblox data model is broken up into 2 main parts:
- The System Entities - Defined by Divblox and used internally to perform certain core functions (Audit Logs, Authentication, File Management, etc)
- The Project Entities - Defined by the developer to serve the purposes of their project
Below is a visual representation of the Divblox System Entities. These entities should not be edited, but rather reused where needed, since they might be affected by future Divblox updates. The developer is free to create relationships to these entities to leverage their existing functionality.
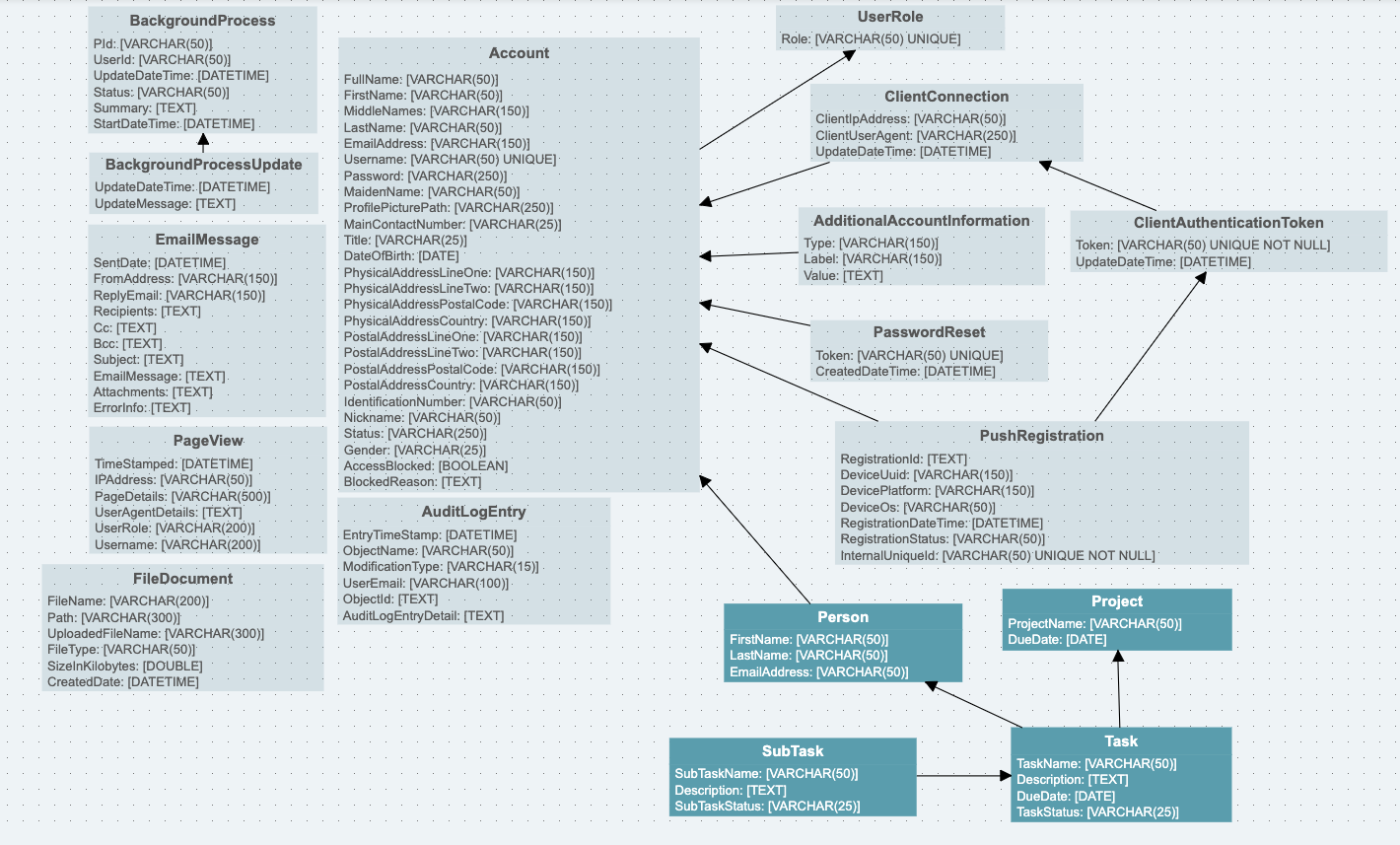
The final data model for your app will be the combination of the system entities and the project entities. Once this is defined, Divblox can generate the app's object relational model and CRUD (Create, Read, Update, Delete) components.
In essence, simply by defining a data model, you already have CRUD ability for every entity in your data model. More on this in later topics.
Below is a visual representation of a complete Divblox data model for the example provided above.
The Divblox ORM (Server side)
ORM Code Generation
Based on the data model, the following is generated or can be generated as required:
- The project's ORM: These are the ORM classes that describe the current underlying database. For each database table there will be corresponding ORM classes that will allow for the CRUD behaviour for that entity. In essence, the ORM caters for the communication with the database without the need for the developer to write sql queries.
- Data model related components: These are the components that allow for exposing the entity's CRUD functionality to the front-end. More on this can be found in the components section.
Code is generated using the following approach:
Each entity will have its own base classes for the ORM. These base classes will always be regenerated when code is generated to ensure that the foundation of your solution is always inline with the database. Each entity will then also have implemented classes that inherit from their base classes. These classes allow for the developer to change the way a certain class works from the default way, since the code in these classes will never be regenerated. This base class/implemented class approach is true for every area where Divblox generates ORM code.
ORM example case
Let's take some time to familiarize ourselves with where this ORM code is generated, how it is structured, and what is available. You can find all the ORM-related classes
in project/assets/php/data_model_orm.
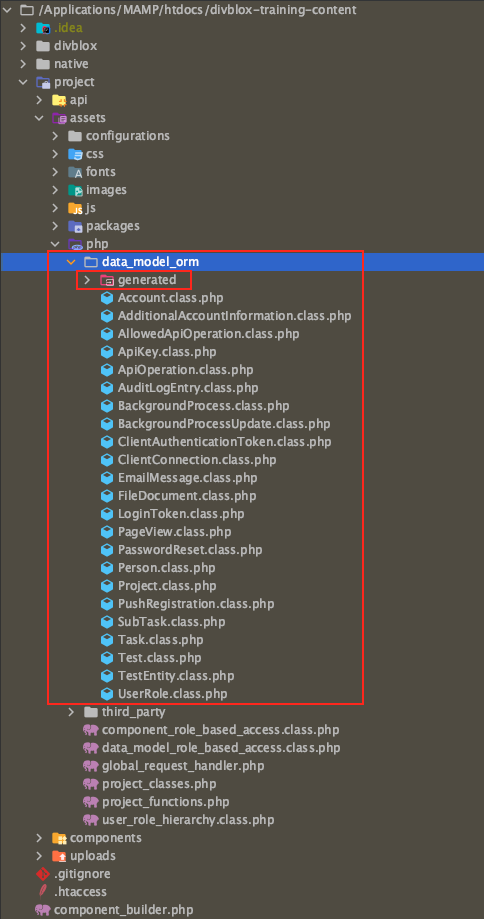
Divblox generates all of the ORM-based code for each entity in EntityNameGen.class.php, and also generates a near-empty EntityName.class.php class for developers to use to override any necessary functionality. We will look through the task entity's TaskGen.class.php file and sift through what functions are available and which a developer will rarely use.
The file contains 3 classes. The last two are only used for background functionality and developers should not worry about them too much. The first class, TaskGen is the
important one that we will discuss.
You are encouraged to peruse through these generated files further to acquant youself with the structure and available functionality. You will see that the first block of code sets all the necessary constants and variables needed in the specific entity. It then initializes each property with default values from the database. Next we will see the following:
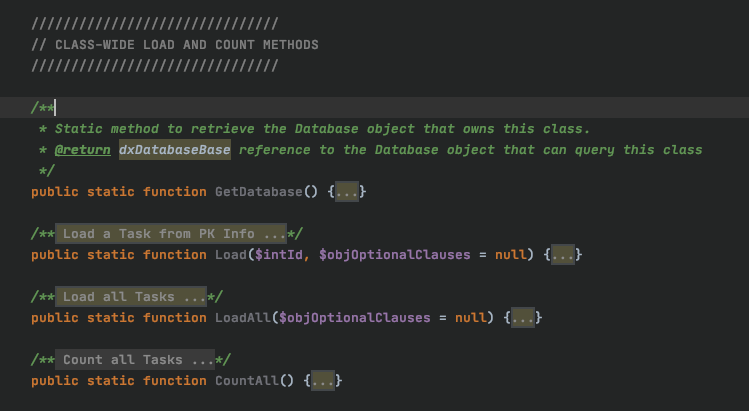
These are the class-wide load and count methods avaiable for this entity. The most commonly used functions are the last 3, where:
- Load() loads an instance of the Task entity by ID, allowing for optional clauses.
- LoadAll() retrieves all instances of the Task entity, again allowing optional clauses.
- CountAll() returns an integer count of rows (instances) of the Task entity table.
We then have Divblox query related methods. The functions BuildQueryStatement(), QueryCursor() and GetSelectedFields() are used in the background by dxQuery. The function QueryArrayCached() is a remnant of old days when PHP was largely inefficient and MySQL queries and results were cached for improved performance. You should not need to use this.
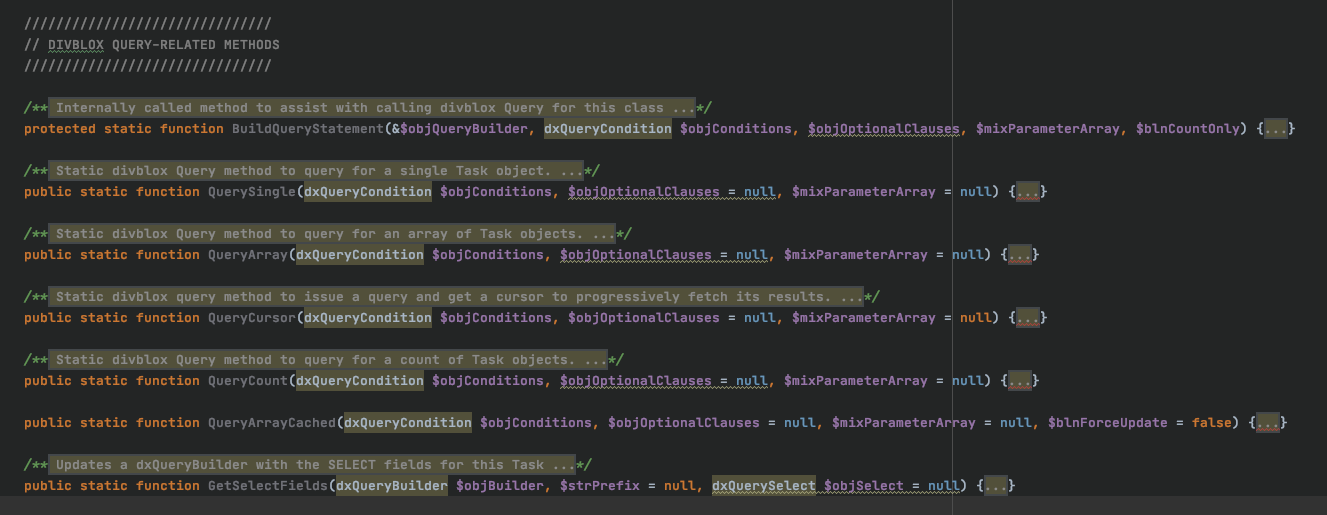
The remaining functions are:
- QuerySingle()
- QuerryArray()
- QueryCount()
which return a single task object, an array of task objects or an integer count of objects respoectively. These functions will be discussed further in the next section.
We then have index-based load methods, which perform 'select' queries by unique ID. These will be different for each entity depending on what relationships you have defined in the data model, as Divblox autogenerates methods for easy loading of relational data as well.
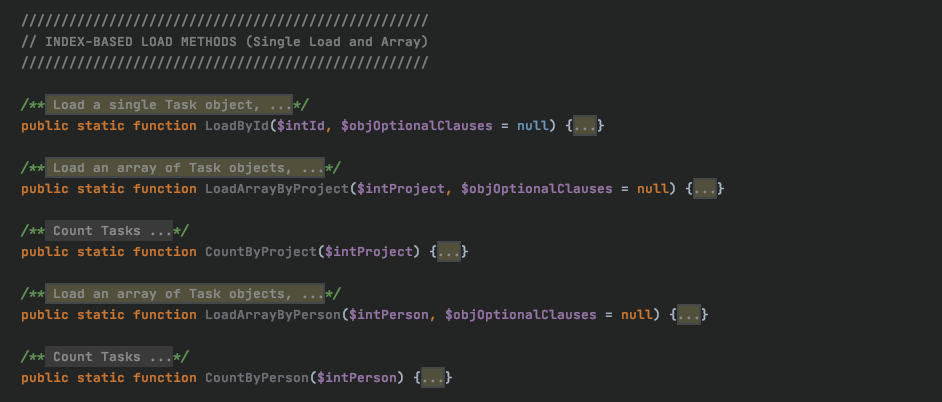
As you can see, we are able to call functions LoadArrayByProject() and LoadArrayByPerson() as each task has a singlular relationship to these two entities. You can also perform "count" operations in a likewise manner.
We then move on to the save, delete and reload methods.
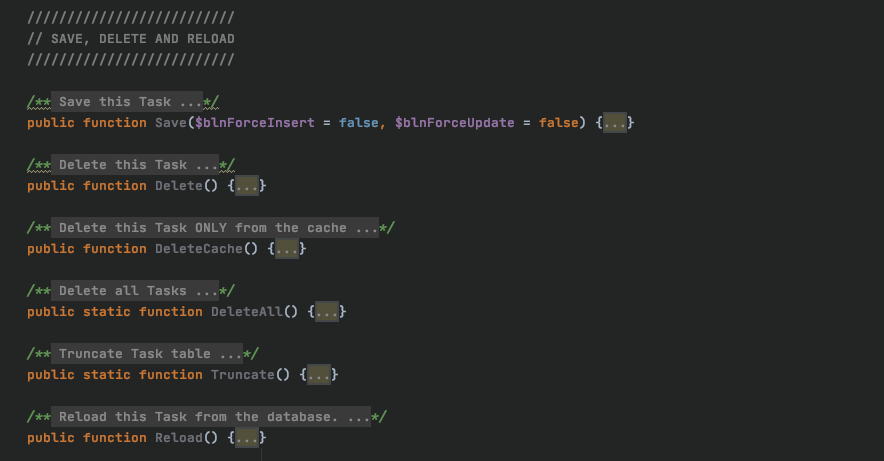
We will again skip over the DeleteCache() function as it won't be used in majority of cases.
The remaining functions allow us to save and delete instances of tasks individually, as well as delete or truncate entire tables. The reload() function reloads the data from the database to try make sure you have the latest version.
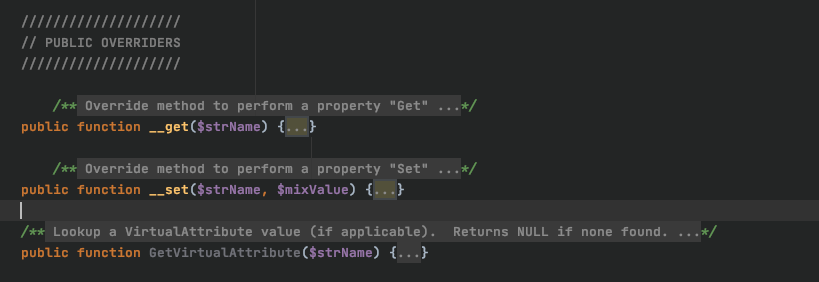
You also have access to the public overriders __get()and __set() which can be used to save you time by allowing dynamic access to attributes in the entity. The getVirtualAttribute() function is also not used as Divblox does not currently use virtualisation.
We also have a set of functions that return information about the database.
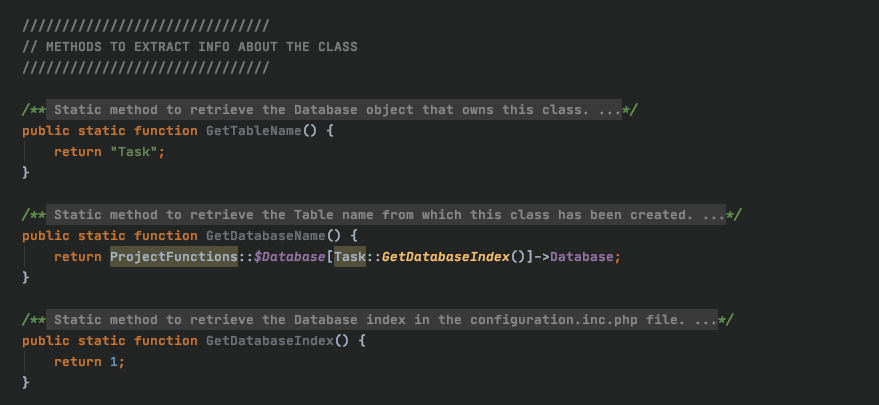
The first two are fairly straight-forward. The third function, getDatabaseIndex() is useful when you have more than one module (database connected to this project), as when working with intermodular relationships it makes quering easier.
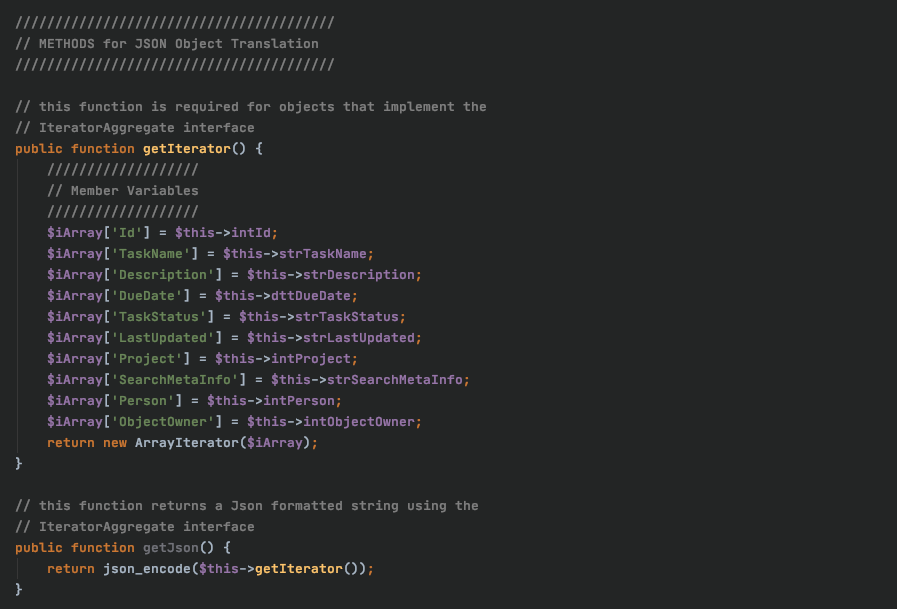
Finally, we have the Iterator() and getJson() functions which work hand in hand. The Iterator() function returns an associative array of the entity attributes, and the `getJson() function converts this to valid JSON and returns that.
Divbox ORM Queries
The querying logic behind all the Load methods in Divblox ORM classes is powered by dxQuery, or dxQ for short. Put simply, dxQ is a completely object oriented API to perform any SELECT-based query on your database to return any result or hierarchy of your ORM objects.
While the ORM classes utilize basic, straightforward SELECT statements in their Load methods, dxQ is capable of infinitely more complex queries. In fact, any SELECT a developer would need to do against a database should be possible with dxQ.
At its core, any dxQ query will return a collection of objects of the same type (e.g. a collection of Task objects). But the power of dxQ is that we can branch beyond this core collection by bringing in any related objects, performing any SQL-based clause (including WHERE, ORDER BY, JOIN, aggregations, etc.) on both the core set of Task rows and any of these related objects rows.
Every code generated class in your ORM will have the three following static dxQuery methods:
- QuerySingle: to perform a dxQuery to return just a single object (typically for queries where you expect only one row)
- QueryArray: to perform a dxQuery to return just an array of objects
- QueryCount: to perform a dxQuery to return an integer of the count of rows (e.g. "COUNT (*)")
All three dxQuery methods can take two parameters, a dxQ Condition and an optional set of dxQ Clauses.
- dxQ Conditions are typically conditions that you would expect to find in a SQL WHERE clause, including Equal, GreaterThan, IsNotNull, etc.
- dxQ Clauses are additional clauses that you could add to alter your SQL statement, including methods to perform SQL equivalents of JOIN, DISTINCT, GROUP BY, ORDER BY and LIMIT.
- And finally, both dxQ Condition and dxQ Clause objects will expect dxQ Node parameters. dxQ Nodes can either be tables, individual columns within the tables, or even association tables. dxQ Node classes for your entire ORM is code generated for you.
The next few examples will examine all three major constructs (dxQ Node, dxQ Condition and dxQ Clause) in greater detail.
Basic Example
note
Notice that dxQuery doesn't have any construct to describe what would normally be your SELECT clause. This is because we take advantage of the code generation process to allow dxQuery to automagically "know" which fields should be SELECT-ed based on the query, conditions and clauses you are performing. This will allow a lot greater flexibility in your data model. Because the framework is now taking care of column names, etc., instead of the developer needing to manually hard code it, you can make changes to columns in your tables without needing to rewrite your dxQuery calls.
dxQuery Nodes
A dxQ Node is any object table or association table (type tables are excluded), as well as any column within those tables. dxQ Node classes for your entire data model are generated for you during the code generation process.
But in addition to this, dxQ Nodes are completely interlinked together, matching the relationships that you have defined as foreign keys (or virtual foreign keys using a relationships script) in your database.
To get at a specific dxQ Node, you will need to call dxQN::ClassName(), where "ClassName" is the name of the class for your table (e.g. "Task"). From there, you can use property getters to get at any column or relationship.
Naming standards for the columns are the same as the naming standards for the public getter/setter properties on the object, itself. So just as $TaskObj->TaskName will get you the "TaskName" property of a Task object, dxQN::Task()->TaskName will refer to the "Task.TaskName" column in the database.
Naming standards for relationships are the same way. The tokenization of the relationship reflected in a class's property and method names will also be reflected in the dxQ Nodes. So just as $TaskObj->PersonObject will get you a Person object which is the manager of a given Task, dxQN::Task()->PersonObject refers to the Task table's row where Task.id = Task.person_id.
And of course, because everything that is linked together in the database, is also linked together in your dxQ Nodes, dxQN::Task()->PersonObject->FirstName would of course refer to the Person's first name of the relevant Task.
dxQuery Conditions
All dxQuery method calls require a dxQ Condition. dxQ Conditions allow you to create a nested/hierarchical set of conditions to describe what essentially becomes your WHERE clause in a SQL query statement.
The following lists the dxQ Condition classes and what parameters they take:
dxQ::All()dxQ::None()dxQ::Equal(dxQNode, Value)dxQ::NotEqual(dxQNode, Value)dxQ::GreaterThan(dxQNode, Value)dxQ::LessThan(dxQNode, Value)dxQ::GreaterOrEqual(dxQNode, Value)dxQ::LessOrEqual(dxQNode, Value)dxQ::IsNull(dxQNode)dxQ::IsNotNull(dxQNode)dxQ::In(dxQNode, array of string/int/datetime)dxQ::Like(dxQNode, string)
For almost all of the above dxQ Conditions, you are comparing a column with some value. The dxQ Node parameter represents that column. However, value can be either a static value (like an integer, a string, a datetime, etc.) or it can be another dxQ Node.
And finally, there are three special dxQ Condition classes which take in any number of additional dxQ Condition classes:
dxQ::AndCondition()dxQ::OrCondition()dxQ::Not()- "Not" can only take in one dxQ Condition class (conditions can be passed in as parameters and/or as arrays). Because And/Or/Not conditions can take in any other condition, including other And/Or/Not conditions, you can embed these conditions into other conditions to create what ends up being a logic tree for your entire SQL Where clause.
Below are a few examples of dxQuery in practice.
dxQuery Clauses
All dxQuery method calls take in an optional set of dxQ Clauses. dxQ Clauses allow you alter the result set by performing the equivalents of most of your major SQL clauses, including JOIN, ORDER BY, GROUP BY and DISTINCT.
The following lists the dxQ Clause classes and parameters they take:
dxQ::OrderBy(array/list of dxQNodes or dxQConditions)dxQ::GroupBy(array/list of dxQNodes)dxQ::Having(dxQSubSqlNode)dxQ::Count(dxQNode, string)dxQ::Minimum(dxQNode, string)dxQ::Maximum(dxQNode, string)dxQ::Average(dxQNode, string)dxQ::Sum(dxQNode, string)dxQ::LimitInfo(integer[, integer = 0])dxQ::Distinct()dxQ::Select(array/list of dxQNodes)
Explanation
OrderBy and GroupBy follow the conventions of SQL ORDER BY and GROUP BY. It takes in a list of one or more dxQ Column Nodes. This list could be a parameterized list and/or an array. Specifically for OrderBy, to specify a dxQ Node that you wish to order by in descending order, add a "false" after the dxQ Node. So for example,
dxQ::OrderBy(dxQN::Task()->Description, false,dxQN::Task()->TaskName)will do the SQL equivalent of "ORDER BY Description DESC, TaskName ASC".Count, Minimum, Maximum , Average and Sum are aggregation-related clauses, and only work when GroupBy is specified.
Having adds a SQL Having clause, which allows you to filter the results of your query based on the results of the aggregation-related functions. Having requires a Subquery, which is a SQL code snippet you create to specify the criteria to filter on. (See the Subquery section later in this tutorial for more information on those).
LimitInfo will limit the result set. The first integer is the maximum number of rows you wish to limit the query to. The optional second integer is the offset (if any).
Distinct will cause the query to be called with SELECT DISTINCT.
The select clause will allow you to manually specify the specific columns you wish to return for the query.
info
All clauses must be wrapped around a single dxQ::Clause() call, which takes in any number of clause classes for your query.
Further example using dxQ::Clause: